
依照慣例,我們會先「定義」一個類別,並設計它所擁有的行為。而今天這個類別,就叫做「關鍵點提取器」,它的用途很明顯 – 單純用來提取影像中的關鍵點 (Key Point),接下來我會詳細說明如何實作該功能!
Table of Contents
撰寫 Header 檔
首先,我們需要創建一個 Header 檔,在裡面簡單定義一個關鍵點提取器,包括它需要設定什麼樣的參數、這些參數的用途,以及關鍵點提取器最重要的行為「從影像中提取關鍵點」。這份 Header 檔的完整內容在下方,我的 Github 也有收錄完整的程式碼。
我們可以簡單命名該 Header 檔為 : KeyPointExtractor.h,這個名稱想傳達的意圖非常清楚明瞭,以下就是該 Header 檔的內容。注意第 1、2、43 行,這幾行的意思是,告訴 C++ 編譯器 : 「如果讀取過該 Header 檔,就不要再讀取一次了」。否則,程式可能會出現一些 Bug!
C++ 的 vector 容器
第 4 行,這邊我們引入了 C++ 的 vector 型別,如圖(一)所示,這個工具可厲害了,它是 C++ 的動態陣列容器。你完全可以不斷把資料存進去,不用擔心長度的問題,因為它會自動調整容量! 但是要注意的是,通常我們再使用 vector 的時候,還是會很小心地管理其中的記憶體,除了避免發生 Bug,還可以提升程式運作的速度、效率。

OpenCV 有提供現成的 KeyPoint 類別
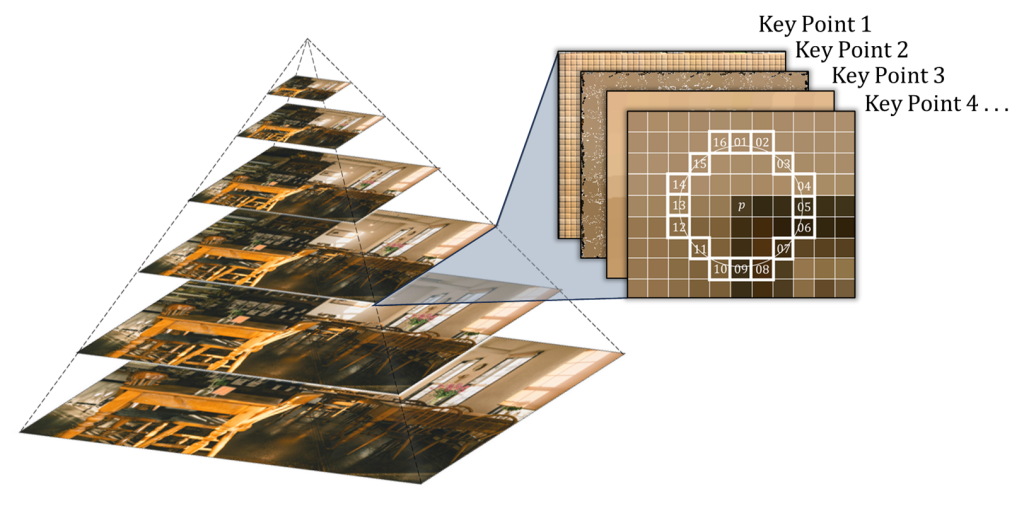
第 6 行是 OpenCV 的 2D 特徵模組,有了它,我們才能夠直接使用 KeyPoint 這個資料型態,不用重複造輪子。任何 KeyPoint 的物件,都包含了幾個重要的變數,例如該關鍵點在影像中的座標位置、在金字塔的哪個層級等,如圖(二)所示。
第 8、9 行很簡單,只是讓我們在撰寫程式碼的時候,能夠寫得簡潔一點,使用 vector 時不用打 std::vector,使用 KeyPoint 的時候不用打 cv::KeyPoint,非常方便。至於第 11 行,那只是我為了區分我自己的 ORB SLAM2 系統,同時也可以避免撞名的問題,這裡就不用理會太多了。
#ifndef KEYPOINTEXTRACTOR_H
#define KEYPOINTEXTRACTOR_H
#include <vector>
#include <opencv2/features2d.hpp>
using namespace cv;
using namespace std;
namespace my_ORB_SLAM2 {
class KeyPointExtractor {
public:
/*
@brief 設定關鍵點提取器
@param[in] nLevels 影像金字塔的層數
@param[in] defaultGridSize 預設每個小格子的尺寸
@param[in] paddingPixels 邊緣向內部填充的 pixels 數量
@param[in] nKeyPoints 總共要提取的關鍵點數量
@param[in] maxTh 一開始提取關鍵點時使用的閾值
@param[in] minTh 放寬標準後,提取關鍵點的閾值 */
KeyPointExtractor(int nLevels, float defaultGridSize, int paddingPixels, int nKeyPoints, int maxTh, int minTh);
~KeyPointExtractor() {};
/*
@brief 提取關鍵點的 function
@param[in, out] keyPointsPerLevel 儲存影像金字塔中,每層影像的關鍵點
@param[in] imagesPerLevel 影像金字塔的每一層影像 */
void extract(
vector<vector<KeyPoint>> &keyPointsPerLevel,
const vector<Mat> &imagesPerLevel
);
private:
int nLevels, paddingPixels, nKeyPoints, maxTh, minTh;
float defaultGridSize;
};
}
#endif宣告一個關鍵點提取器類別
以上就是完整的 Header 檔內容,相信文檔中的註解已經解釋得很清楚了,但我還是會詳細地講解每一個參數所代表的意義!
首先,我們當然得宣告一個 KeyPointExtractor 類別,這個類別有很多個重要的私有成員變數 : 「nLevels, paddingPixels, nKeyPoints, maxTh, minTh」。有了這些變數,一個 KeyPointExtractor 物件才能夠順利地進行關鍵點提取的動作,如圖(三)所示。
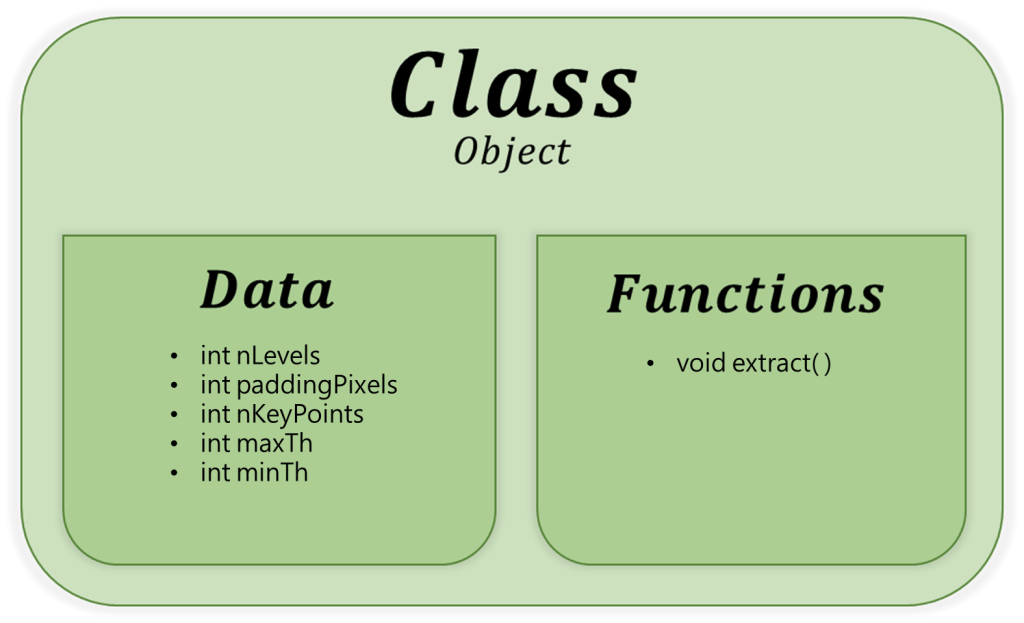
KeyPointExtractor 類別有很多個重要的私有成員變數,nLevels, paddingPixels, nKeyPoints, maxTh, minTh。有了這些變數,一個 KeyPointExtractor 物件才能夠順利地進行關鍵點提取的動作。為什麼要抽離參數,而不是直接傳整個金字塔物件?

你有注意到嗎? nLevels、nKeyPoints 這兩個變數其實是來自於我們之前製作的 ImagePyramid 。為什麼我不直接把 ImagePyramid 物件 assign 給關鍵點提取器,讓關鍵點提取器可以直接使用影像金字塔的參數呢? 因為這樣模組之間的界線才會乾淨,把不同功能設計成獨立的模組,不互相依賴,維護起來就會很少踩雷。
其實,這只是因為每個程式設計師的習慣都不一樣。如果你把 ImagePyramid 物件直接塞進關鍵點提取器,聽起來很方便,因為少了幾個參數傳來傳去。但是代價是 : 影像金字塔和關鍵點提取器綁死了! 如果今天我突然想更改金字塔的相關架構或演算法,那連關鍵點提取器都必須跟著大改,這就是設計上的鐵鍊效應。
還有,如果這類的模組設計得像洋蔥,一層包一層,debug 起來就跟剝洋蔥一樣,一把眼淚一把鼻涕,我才不想自虐。
關鍵點提取器的私有變數介紹
雖然前面說,我們會把影像金字塔的參數傳給關鍵點提取器,但這並不代表關鍵點提取器依賴於影像金字塔,我們只是要確保前面模組採用的參數和後面模組具有一致性就可以,接下來我會正式介紹關鍵點提取器的每一個私有變數 :
nLevels:
影像金字塔的層數。這個參數會在影像金字塔設定完後,輸入給關鍵點提取器。其實原因很簡單,就是關鍵點提取器會根據金字塔的層數,按照順序取得每一層影像。取得一層影像後,對其提取關鍵點。就這樣,最後,每一層影像都會有自己的關鍵點集合。

defaultGridSize:
每個小格子的預設尺寸。在 ORB SLAM2 中預設是 30,也就是說,理想情況下,每個 Grid 的尺寸應該要是 30 * 30。但是實際情況下不一定,例如可提取關鍵點的範圍,其寬高為640 * 480,那我們會先評估總共可以分割成幾列、行。640.0/30.0 = 21.33、480.0/30.0 = 16.0,所以得到是 21 行、16 列。此時,再用640.0 / 21.0 = 30.47、480.0/16.0 = 30.0,無條件進位,確保所有 Grid 涵蓋到所有可以體取關鍵點的區域,得到每個 Grid 的尺寸為31 * 30。
另外,由於我們不能忽略 Grid 邊界可能存在的關鍵點,所以實際提取時會再向四個方向擴增 3 pixels,如圖(六)所示。

paddingPixels:
邊緣向內部填充的 pixels 數量。前一篇文章我們有提到,所有 Grid 外面還有預留一些空間,而這個預留的區域寬度,就是paddingPixels。ORB SLAM2 中,這個數值是 19,這提供了足夠的空間來計算關鍵點的描述子,如圖(七)所示。

nKeyPoints:
總共要提取的關鍵點數量,在 ORB SLAM2 中是設置為 2000。這個參數同樣是來自於影像金字塔,但是它對於關鍵點提取器的重要程度沒那麼大。它只是讓關鍵點提取器可以稍微度量一下每一層要提取的關鍵點數量,預先分配好 vector 容器的記憶體空間,避免動態擴增記憶體帶來的性能開銷,確保程式的穩定。
maxTh:
一開始提取關鍵點時使用的閾值。這也是前一篇文章有提到的,當我們針對一個 Grid 提取關鍵點時,會先使用這個閾值,具體來說要設置多少任你決定,ORB SLAM2 是設置 20,可以參考一下!
minTh:
放寬標準後,提取關鍵點的閾值,ORB SLAM2 通常是設置為 7。如果用maxTh提取不到關鍵點,那我們會先退而求其次,降低閾值後,再提取一次。因為我們確保在比較少紋理的地方也可以提取到關鍵點,不浪費任何有用的資訊。值得注意的是,如果連比較寬鬆的閾值都無法讓我們提取到關鍵點,那就放棄這個 Grid 吧! 因為繼續降低閾值所提取到的關鍵點品質會很差。
關鍵點提取器的 Function 介紹
說明完私有變數後,我們終於可以來說說關鍵點提取器的 Function 了。這個 Function 叫做 extract,其功能很明顯,就是要提取影像中的關鍵點。以下是這個 Function 的格式 :
/*
@brief 提取關鍵點的 function
@param[in, out] keyPointsPerLevel 儲存影像金字塔中,每層影像的關鍵點
@param[in] imagesPerLevel 影像金字塔的每一層影像 */
void extract(
vector<vector<KeyPoint>> &keyPointsPerLevel,
const vector<Mat> &imagesPerLevel
);我接下來會仔細介紹每一個參數的用途,但這邊要先提醒一下,imagesPerLevel 這個參數也是來自於影像金字塔,如圖(四)所示,道理很簡單,因為關鍵點提取器會為每一層影像提取關鍵點!
keyPointsPerLevel:
用於儲存影像金字塔中,每層影像的關鍵點。這個容器,其實很好理解,它的層數和影像金字塔的層數一樣,且每一層都會儲存一組關鍵點。例如,第一層儲存的所有關鍵點,對應於影像金字塔中的第一層影像,以此類推。
只不過我們需要先準備一個空的vector<vector<KeyPoint>>容器,也就是keyPointsPerLevel。傳入void extract後,每一層影像的關鍵點資訊都會儲存到keyPointsPerLevel中,如圖(八)所示。
為什麼可以直接操作keyPointsPerLevel呢? 因為我在變數名稱前面加了 & 符號,這代表我不會重新複製一份keyPointsPerLevel傳入 Function,而是直接操作keyPointsPerLevel這個變數本身。

vector<vector<KeyPoint>> 這個容器的概念其實很簡單,你可以把它想像成好幾個排在一起的資料夾,每個資料夾都擁有一個索引編號。除此之外,每個資料夾也都會儲存一堆關鍵點,例如索引為 0 的資料夾,會儲存影像金字塔中,level 0 的影像所對應的 Key Points,以此類推。imagesPerLevel: 影像金字塔的每一層影像,如圖(九)所示。這個參數非常直觀,關鍵點提取器需要每一層影像的資料,才能夠為每一層影像提取關鍵點。
與keyPointsPerLevel類似,我同樣在變數前面加了 & 符號,代表我不複製影像金字塔的影像資料傳入 Function,而是傳入原本影像金字塔中的影像資料,藉此避免複製數據帶來的性能開銷。但是不太一樣的地方是,我也為了安全性,在變數前面還有加上 const 關鍵字,這是告訴 Function : 「你只能夠讀取這些影像資料,但是不能修改它們」。

關鍵點提取器的定義 (Source 檔)
以下就是關鍵點提取器的建構子、Function 的實作細節,包含設定私有變數、關鍵點提取演算法等。因為關鍵點的提取流程演算法在本文章以及前一篇文章都有詳細提及,程式碼裡面也有詳細的註解,所以這邊就不贅述囉! 好好閱讀吧!
#include "myORB-SLAM2/KeyPointExtractor.h"
namespace my_ORB_SLAM2 {
/*
@brief 設定關鍵點提取器
@param[in] nLevels 影像金字塔的層數
@param[in] defaultGridSize 預設每個小格子的尺寸
@param[in] paddingPixels 邊緣向內部填充的 pixels 數量
@param[in] nKeyPoints 總共要提取的關鍵點數量
@param[in] maxTh 一開始提取關鍵點時使用的閾值
@param[in] minTh 放寬標準後,提取關鍵點的閾值
*/
KeyPointExtractor::KeyPointExtractor(int nLevels, float defaultGridSize, int paddingPixels, int nKeyPoints, int maxTh, int minTh) {
this->nLevels = nLevels;
this->defaultGridSize = defaultGridSize;
this->paddingPixels = paddingPixels;
this->nKeyPoints = nKeyPoints;
this->maxTh = maxTh;
this->minTh = minTh;
};
/*
@brief 提取關鍵點的 function
@param[in, out] keyPointsPerLavel 儲存影像金字塔中,每層影像的關鍵點
@param[in] imagesPerLevel 影像金字塔的每一層影像 */
void KeyPointExtractor::extract(
vector<vector<KeyPoint>> &keyPointsPerLevel,
const vector<Mat> &imagesPerLevel
) {
// 設定 keyPointsPerLevel 大小為影像金字塔層數
keyPointsPerLevel.resize(this->nLevels);
// 遍歷每一層影像
for(size_t level = 0; level < this->nLevels; level++) {
// 設定可提取關鍵點的邊界
int minBorderX = paddingPixels - 3;
int minBorderY = minBorderX;
int maxBorderX = imagesPerLevel[level].cols - paddingPixels + 3;
int maxBorderY = imagesPerLevel[level].rows - paddingPixels + 3;
// keyPoints 用於儲存該層影像的關鍵點,並預留比預計提取之關鍵點數量多 10 倍的空間
// 避免動態擴增空間造成的性能消耗
vector<KeyPoint> keyPoints;
keyPoints.reserve(nKeyPoints * 10);
// 計算關鍵點提取範圍的長寬
float width = float(maxBorderX - minBorderX);
float height = float(maxBorderY - minBorderY);
// 計算目前的關鍵點提取範圍可以畫分成幾個行、列
int nCols = int(width / defaultGridSize);
int nRows = int(height / defaultGridSize);
// 計算每個小格子的寬、高
int gridWidth = ceil(width / nCols);
int gridHeight = ceil(height / nRows);
// 遍歷每個 grid
for(size_t row = 0; row < nRows; row++) {
// 計算 FAST 關鍵點需要半徑為 3 的圓形範圍
// 所以每個 grid 的邊界需要暫時向外擴增 3 單位
// 才可以確保沒丟失邊界的關鍵點訊息
int ymin = minBorderY + row * gridHeight;
int ymax = ymin + gridHeight + 6;
// 如果 ymin 超過 maxBorderY - 6,代表沒有足夠的半徑 3 可以計算關鍵點,跳過
if(ymin > maxBorderY - 6) { continue; }
// 限制 ymax 不要超過關鍵點的提取範圍
if(ymax > maxBorderY) { ymax = maxBorderY; }
// 前置步驟和上面一樣
for(size_t col = 0; col < nCols; col++) {
int xmin = minBorderX + col * gridWidth;
int xmax = xmin + gridWidth + 6;
if(xmin > maxBorderX - 6) { continue; }
if(xmax > maxBorderX) { xmax = maxBorderX; }
// 提取該 grid 的關鍵點
vector<KeyPoint> gridKeyPoints;
gridKeyPoints.reserve(32);
FAST(
imagesPerLevel[level].rowRange(ymin, ymax).colRange(xmin, xmax),
gridKeyPoints,
maxTh
);
// 如果沒有檢測到關鍵點,就降低閾值在提取一次
if(gridKeyPoints.empty()) {
FAST(
imagesPerLevel[level].rowRange(ymin, ymax).colRange(xmin, xmax),
gridKeyPoints,
minTh
);
}
// 因為目前提取到的關鍵點做標是相對於該 grid 的,所以需要恢復到相對於整張影像的座標
if(!gridKeyPoints.empty()) {
for(vector<KeyPoint>::iterator vit = gridKeyPoints.begin(); vit != gridKeyPoints.end(); vit++) {
(*vit).pt.x += col * gridWidth;
(*vit).pt.y += row * gridHeight;
keyPoints.push_back(*vit);
}
}
}
}
// 修飾該層最後提取到的關鍵點
for(vector<KeyPoint>::iterator vit = keyPoints.begin(); vit != keyPoints.end(); vit++) {
(*vit).pt.x += minBorderX; // 增加 offset
(*vit).pt.y += minBorderY; // 增加 offset
(*vit).octave = level; // 設定關鍵點所屬的金字塔層級
}
// 儲存該層的 KeyPoints
keyPointsPerLevel[level] = keyPoints;
}
}
}比較 OpenCV 與 ORB SLAM2 的關鍵點提取結果
好了,我們耗費了那麼多時間在釐清 ORB SLAM2 中關鍵點該如何提取,總該見識一下究竟 ORB SLAM2 的關鍵點提取結果和 OpenCV 內建的關鍵點提取結果有什麼差異吧? 我們觀察一下圖(十),我只取一個地方進行比較,我們可以發現,ORB SLAM2 的提取結果 (上圖),它能夠比 OpenCV (下圖) 提取到更多紋理比較弱的地方,不浪費任何區域的資訊。

雖然圖(十)中,兩張圖的結果看起來差不多,但你仔細一個個地方比較,就會發現差異了! OpenCV 少提取到很多關鍵點,因為它是直接對整張圖做運算,而非像 ORB SLAM2 那樣考慮局部區域的狀況,所以少了一點彈性,只能使用同一個閾值來提取關鍵點。
為什麼關鍵點的密度和數量看起來那麼大?
事實上,關鍵點的提取只是 ORB SLAM2 中,特徵提取的初始步驟。後續,我們會了解如何利用一種資料結構「四叉樹」對關鍵點進行均勻化,並減少過多的關鍵點。在圖(十)中,關鍵點稠密的地方,其實不需要那麼多關鍵點,有很多區域,其實只要用少數的關鍵點就能夠清楚表達該區域的空間結構,過多的關鍵點只會導致誤差增加。
經過均勻化之後,關鍵點的層次和分布將會更均勻,有助於表達空間的幾何結構!

[…] 上一篇文章,「第 6 天 : 實作關鍵點 (Key Point) 提取功能」提到,單純地提取關鍵點,會造成過度密集、數量太多的情況,進一步產生冗餘的關鍵點,降低系統穩定度。 […]